Storage Options
This guide describes how to use Amazon EFS and Amazon FSx for Lustre with Kubeflow.
Amazon EFS
Amazon EFS is managed NFS in AWS. Amazon EFS supports ReadWriteMany access mode, which means the volume can be mounted as read-write by many nodes. It is very useful for creating a shared filesystem that can be mounted into pods such as Jupyter. For example, one group can share datasets or models across an entire team.
By default, the Amazon EFS CSI driver is not enabled and you need to follow steps to install it.
Deploy the Amazon EFS CSI Plugin
git clone https://github.com/kubeflow/manifests
cd manifests/aws
kubectl apply -k aws-efs-csi-driver/base
Static Provisioning
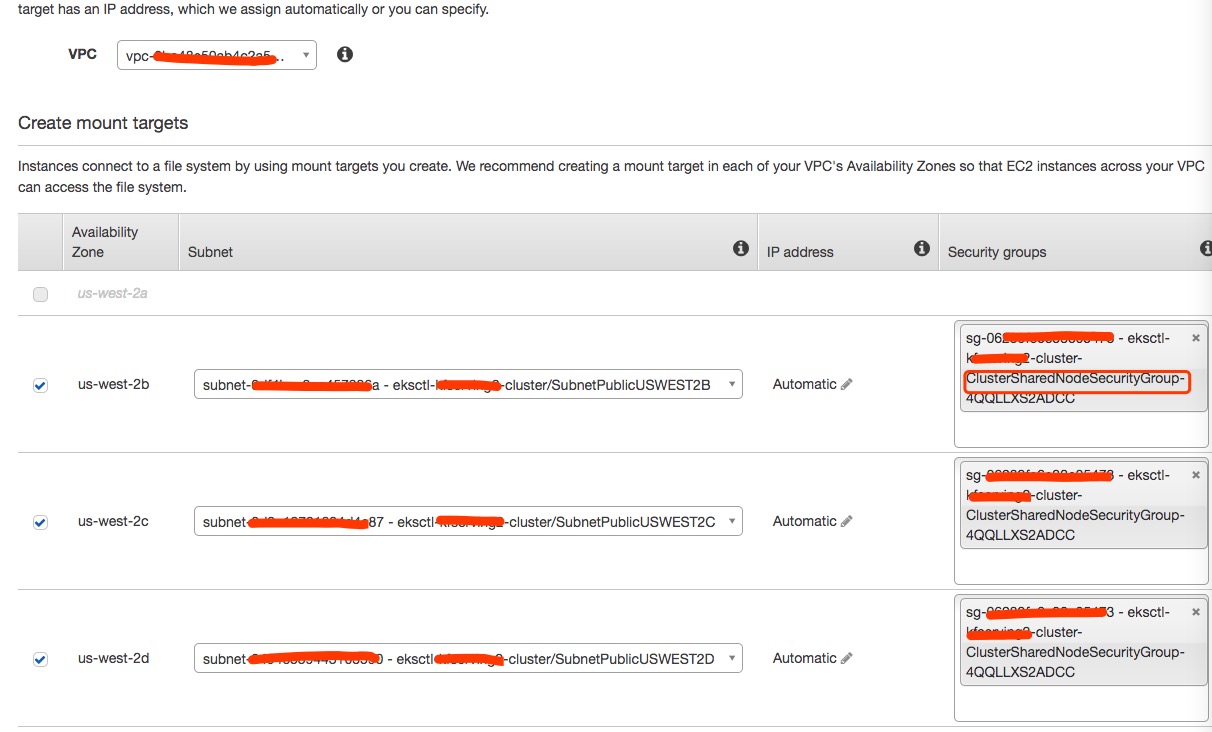
You can provision a new Amazon EFS file system in the Amazon EFS console. Choose the VPC, Subnet IDs, and provisioning mode to use.
Ensure that in the Security Groups configuration that traffic to NFS port 2049 is allowed.
Once created, retrieve the new file system ID and use it to create PersistentVolume and PersistentVolumeClaim objects.
In this example, eksctl was used to provision the cluster. You can choose ClusterSharedNodeSecurityGroup.
If it’s not already in place, specify a storage class for EFS and create it with kubectl.
cat << EOF > efs-sc.yaml
apiVersion: storage.k8s.io/v1
metadata:
name: efs-sc
provisioner: efs.csi.aws.com
EOF
kubectl apply -f efs-sc.yaml
To create a volume, replace <your_efs_id> with the file system id from the creation above and create it with kubectl.
EFS_ID=<your_efs_id>
cat << EOF > efs-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: efs-pv
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
csi:
driver: efs.csi.aws.com
volumeHandle: ${EFS_ID}
EOF
kubectl apply -f efs-pv.yaml
Finally, create a claim on the volume for use. Replace <your_namespace> with your namespace and create the PVC with kubectl.
NAMESPACE=<your_namespace>
cat << EOF > efs-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: efs-claim
namespace: ${NAMESPACE}
spec:
accessModes:
- ReadWriteMany
storageClassName: efs-sc
resources:
requests:
storage: 5Gi
EOF
kubectl apply -f efs-claim.yaml
By default, new Amazon EFS file systems are owned by root:root, and only the root user (UID 0) has read-write-execute permissions. If your containers are not running as root, you must change the Amazon EFS file system permissions to allow other users to modify the file system.
In order to share EFS between notebooks, you can create a sample pod as shown below to change permission the file system permissions. If you use EFS for other purposes (e.g. sharing data across pipelines), you don’t need this step.
Replace <your_namespace> with your namespace and create the job with kubectl.
NAMESPACE=<your_namespace>
cat << EOF > job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: set-permission
namespace: ${NAMESPACE}
spec:
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
restartPolicy: Never
containers:
- name: app
image: centos
command: ["/bin/sh"]
args:
- "-c"
- "chmod 2775 /data && chown root:users /data"
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: efs-claim
EOF
kubectl apply -f job.yaml
To use Amazon EFS as a notebook volume when you create Jupyter notebooks, specify the PersistentVolumeClaim name.
Amazon FSx for Lustre
Amazon FSx for Lustre provides a high-performance file system optimized for fast processing for machine learning and high performance computing (HPC) workloads. AWS FSx for Lustre CSI Driver can help Kubernetes users easily leverage this service.
Lustre is another file system that supports ReadWriteMany. One difference between Amazon EFS and Lustre is that Lustre can be used to cache training data with direct connectivity to Amazon S3 as the backing store. With this configuration, you don’t need to transfer data to the file system before using the volume.
By default, the Amazon FSx CSI driver is not enabled and you need to follow steps to install it.
Deploy the Amazon FSx CSI Plugin
Ensure your driver will have the required IAM permissions. For details, refer to the project documentation.
git clone https://github.com/kubeflow/manifests
cd manifests/aws
kubectl apply -k aws-fsx-csi-driver/base
Static Provisioning
You can statically provision Amazon FSx for Lustre and then use the file system ID, DNS name and mount name to create PersistentVolume and PersistentVolumeClaim objects.
Amazon FSx for Lustre provides both scratch and persistent deployment options. Choose the deployment which best suits your needs. For more details on deployment options, see the documentation.
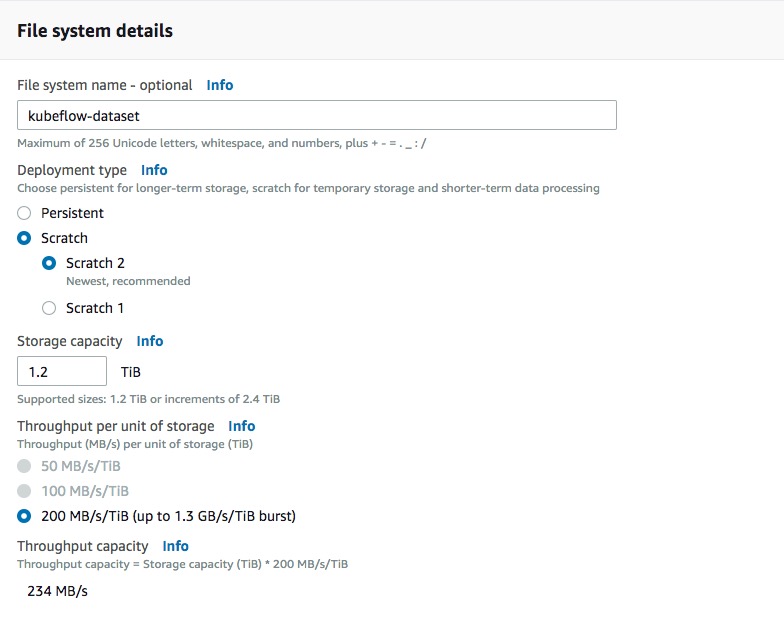
Persistent file systems in FSx are replicated within a single availability zone. Select the appropriate subnet based on your cluster’s node group configuration.
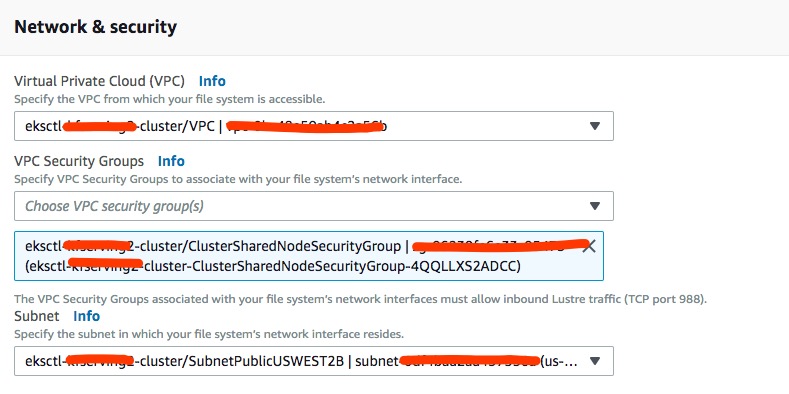
Once the file system is created, you can retrieve “File system ID”, “DNS name” and “Mount name” for the configuration steps below.
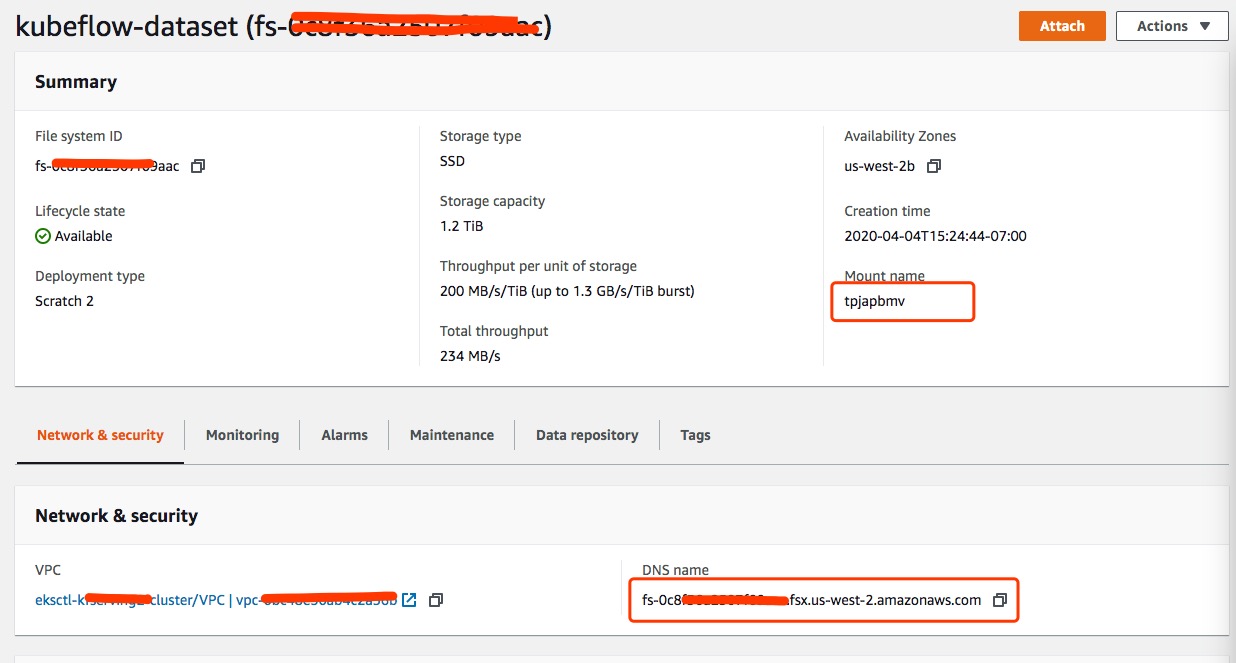
You can optionally retrieve this information with the aws CLI:
aws fsx describe-file-systems
Retrieve the FileSystemId, DNSName, and MountName values.
To create a volume, replace <file_system_id>, <dns_name>, and <mount_name> with your values and create it with kubectl.
FS_ID=<file_system_id>
DNS_NAME=<dns_name>
MOUNT_NAME=<mount_name>
cat << EOF > fsx-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: fsx-pv
spec:
capacity:
storage: 1200Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
mountOptions:
- flock
persistentVolumeReclaimPolicy: Recycle
csi:
driver: fsx.csi.aws.com
volumeHandle: ${FS_ID}
volumeAttributes:
dnsname: ${DNS_NAME}
mountname: ${MOUNT_NAME}
EOF
kubectl apply -f fsx-pv.yaml
Now you can create a claim on the volume for use. Replace <your_namespace> with your namespace and create the PVC with kubectl.
NAMESPACE=<your_namespace>
cat << EOF > fsx-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-claim
namespace: <your_namespace>
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 1200Gi
volumeName: fsx-pv
EOF
kubectl apply -f fsx-pvc.yaml
Dynamic Provisioning
You can optionally dynamically provision Amazon FSx for Lustre filesystems. The SecurityGroupId and SubnetId are required. Amazon FSx for Lustre is an Availability Zone-based file system, and you can only pass one subnet in this dynamic configuration. This means you need to create a cluster in single Availability Zone, which makes sense for machine learning workloads.
If you already have a training dataset in Amazon S3, you can configure it for use by Amazon FSx for Lustre as a data repository and your file system will be ready with the training dataset.
For dynamic provisioning, see the example in the project repo here.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.