Kubeflow Pipelines on AWS
Authenticate Kubeflow Pipeline using SDK inside cluster
In v1.1.0, in-cluster communication from notebook to Kubeflow Pipeline is not supported in this phase. In order to use kfp as previous, user needs to pass a cookie to KFP for communication as a workaround.
You can follow following steps to get cookie from your browser after you login Kubeflow. Following examples uses Chrome browser.
Note: You have to use images in AWS Jupyter Notebook because it includes a critical SDK fix here.
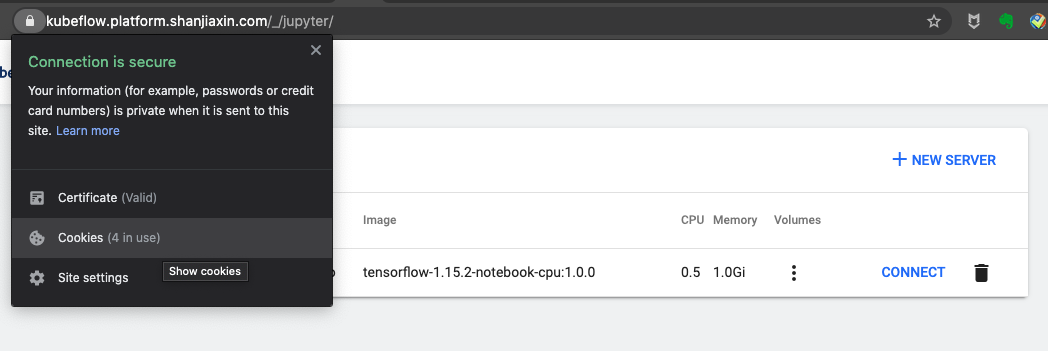
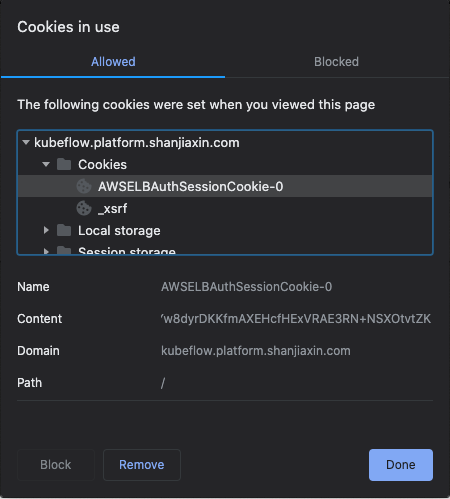
Once you get cookie, you can easily authenticate kfp by passing the cookies. Please look at code snippets based on the manifest you use.
To get <aws_alb_host>, please run kubectl get ingress -n istio-system and get value from ADDRESS field.
import kfp
authservice_session='authservice_session=<cookie>'
client = kfp.Client(host='http://<aws_alb_host>/pipeline', cookies=authservice_session)
client.list_experiments(namespace="<your_namespace>")
- cognito https://raw.githubusercontent.com/kubeflow/manifests/v1.2-branch/kfdef/kfctl_aws_cognito.v1.2.0.yaml
import kfp
alb_session_cookie0='AWSELBAuthSessionCookie-0=<cookie0>'
alb_session_cookie1='AWSELBAuthSessionCookie-1=<cookie1>'
client = kfp.Client(host='https://<aws_alb_host>/pipeline', cookies=f"{alb_session_cookie0};{alb_session_cookie1}")
client.list_experiments(namespace="<your_namespace>")
Authenticate Kubeflow Pipeline using SDK outside cluster
To do programmatic authentication with Dex, refer to the following comments under the #140 issue in the kfctl repository: #140 (comment) and #140 (comment).
- cognito https://raw.githubusercontent.com/kubeflow/manifests/v1.2-branch/kfdef/kfctl_aws_cognito.v1.2.0.yaml
You can still retrieve session cookie and pass to backend like we do [here] (#authenticate-kubeflow-pipeline-using-sdk-inside-cluster)
If you are looking for end to end experience, this is working in progress. Once feat(sdk): Enable AWS ALB authentication in KFP SDK Client PR is merged, user can pass Cognito user username and password to authenticate KFP via AWS Application Load Balancer.
S3 Access from Kubeflow Pipelines
Currently, it’s still recommended to use aws credentials or kube2iam to managed S3 access from Kubeflow Pipelines. IAM Role for Service Accounts requires applications to use latest AWS SDK to support assume-web-identity-role, we are still working on it. Track progress in issue #3405
A Kubernetes Secret is required by Kubeflow Pipelines and applications to access S3. Make sure it has S3 read and write access.
apiVersion: v1
kind: Secret
metadata:
name: aws-secret
namespace: kubeflow
type: Opaque
data:
AWS_ACCESS_KEY_ID: <YOUR_BASE64_ACCESS_KEY>
AWS_SECRET_ACCESS_KEY: <YOUR_BASE64_SECRET_ACCESS>
- YOUR_BASE64_ACCESS_KEY: Base64 string of
AWS_ACCESS_KEY_ID - YOUR_BASE64_SECRET_ACCESS: Base64 string of
AWS_SECRET_ACCESS_KEY
Note: To get base64 string, run
echo -n $AWS_ACCESS_KEY_ID | base64
Configure containers to use AWS credentials
If you write any files to S3 in your application, use use_aws_secret to attach an AWS secret to access S3.
import kfp
from kfp import components
from kfp import dsl
from kfp.aws import use_aws_secret
def iris_comp():
return kfp.dsl.ContainerOp(
.....
output_artifact_paths={'mlpipeline-ui-metadata': '/mlpipeline-ui-metadata.json'}
)
@dsl.pipeline(
name='IRIS Classification pipeline',
description='IRIS Classification using LR in SKLEARN'
)
def iris_pipeline():
iris_task = iris_comp().apply(use_aws_secret('aws-secret', 'AWS_ACCESS_KEY_ID', 'AWS_SECRET_ACCESS_KEY'))
Support S3 Artifact Store
Kubeflow Pipelines supports different artifact viewers. You can create files in S3 and reference them in output artifacts in your application as follows:
metadata = {
'outputs' : [
{
'source': 's3://bucket/kubeflow/README.md',
'type': 'markdown',
},
{
'type': 'confusion_matrix',
'format': 'csv',
'schema': [
{'name': 'target', 'type': 'CATEGORY'},
{'name': 'predicted', 'type': 'CATEGORY'},
{'name': 'count', 'type': 'NUMBER'},
],
'source': s3://bucket/confusion_matrics.csv,
# Convert vocab to string because for bealean values we want "True|False" to match csv data.
'labels': list(map(str, vocab)),
},
{
'type': 'tensorboard',
'source': s3://bucket/tb-events,
}
]
}
with file_io.FileIO('/tmp/mlpipeline-ui-metadata.json', 'w') as f:
json.dump(metadata, f)
In order for ml-pipeline-ui to read these artifacts:
-
Create a Kubernetes secret
aws-secretinkubeflownamespace. Follow instructions here. -
Update deployment
ml-pipeline-uito use AWS credential environment variables by runningkubectl edit deployment ml-pipeline-ui -n kubeflow.apiVersion: extensions/v1beta1 kind: Deployment metadata: name: ml-pipeline-ui namespace: kubeflow ... spec: template: spec: containers: - env: - name: AWS_ACCESS_KEY_ID valueFrom: secretKeyRef: key: AWS_ACCESS_KEY_ID name: aws-secret - name: AWS_SECRET_ACCESS_KEY valueFrom: secretKeyRef: key: AWS_SECRET_ACCESS_KEY name: aws-secret .... image: gcr.io/ml-pipeline/frontend:0.2.0 name: ml-pipeline-ui
Here’s an example.
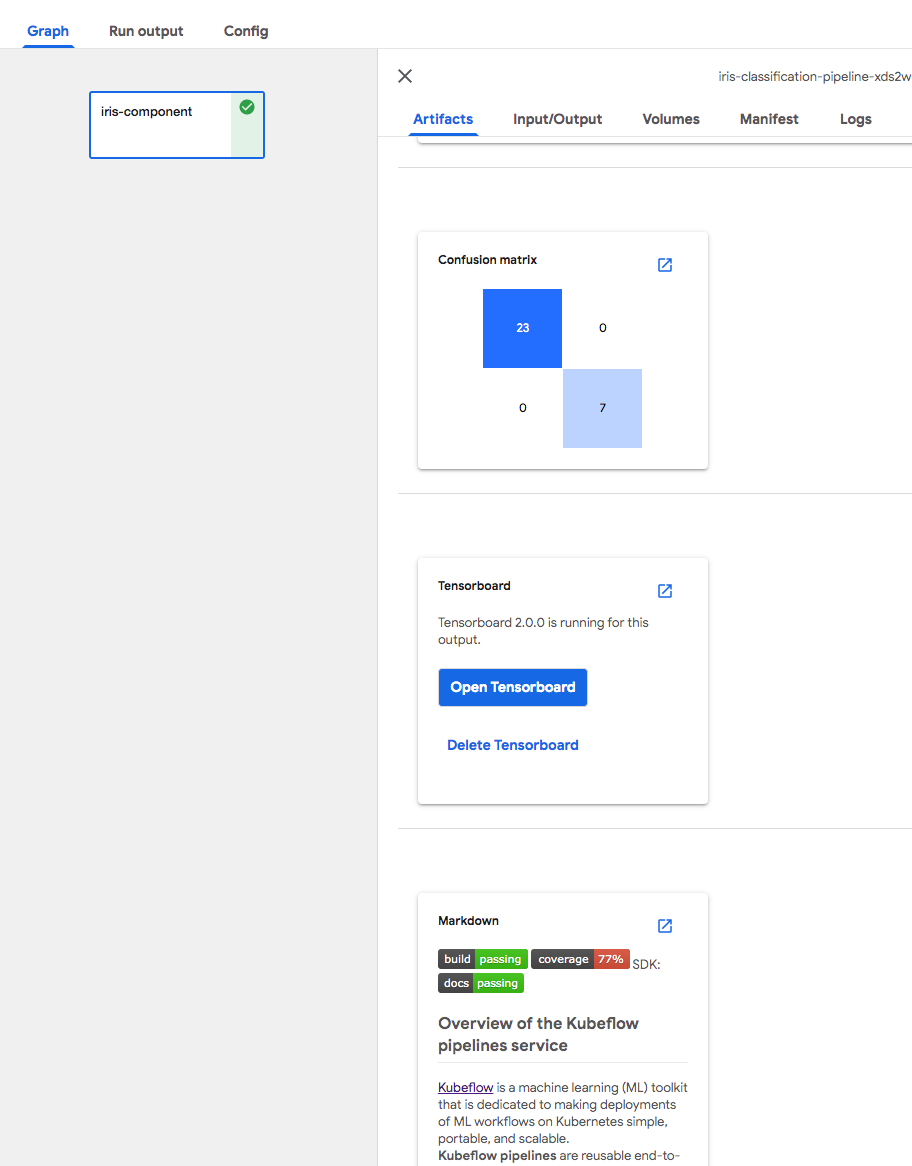
Support TensorBoard in Kubeflow Pipelines
TensorBoard needs some extra settings on AWS like below:
-
Create a Kubernetes secret
aws-secretin thekubeflownamespace. Follow instructions here. -
Create a ConfigMap to store the configuration of TensorBoard on your cluster. Replace
<your_region>with your S3 region.apiVersion: v1 kind: ConfigMap metadata: name: ml-pipeline-ui-viewer-template data: viewer-tensorboard-template.json: | { "spec": { "containers": [ { "env": [ { "name": "AWS_ACCESS_KEY_ID", "valueFrom": { "secretKeyRef": { "name": "aws-secret", "key": "AWS_ACCESS_KEY_ID" } } }, { "name": "AWS_SECRET_ACCESS_KEY", "valueFrom": { "secretKeyRef": { "name": "aws-secret", "key": "AWS_SECRET_ACCESS_KEY" } } }, { "name": "AWS_REGION", "value": "<your_region>" } ] } ] } } -
Update the
ml-pipeline-uideployment to use the ConfigMap by runningkubectl edit deployment ml-pipeline-ui -n kubeflow.apiVersion: extensions/v1beta1 kind: Deployment metadata: name: ml-pipeline-ui namespace: kubeflow ... spec: template: spec: containers: - env: - name: VIEWER_TENSORBOARD_POD_TEMPLATE_SPEC_PATH value: /etc/config/viewer-tensorboard-template.json .... volumeMounts: - mountPath: /etc/config name: config-volume ..... volumes: - configMap: defaultMode: 420 name: ml-pipeline-ui-viewer-template name: config-volume
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.